
What on earth is a facet?
A facet is a piece of information about an entity that can be used to categorise it. Take for example a piece of fruit, it might have facets relating to its colour, size, weight, etc. Facets are a way of describing an entity in a structured way and are often used in search engines to allow users to filter results.
Let's continue with the fruit theme, imagine that you are a fruit vendor and you have created a website to sell your fruit. Customers love the quality of your produce, but they are often overwhelmed by the sheer variety of fruit that you offer. You think of other websites that sell products and how they allow users to filter their results by various attributes, such as price, colour, etc. You decide to implement this feature on your website too, and you want customers to be able to drill down to the type of fruit they wish to consume easily, you also want your users to see at each stage how many fruits will match the criteria they are applying.
You're a wiz with UI, so you squirrel away and create all the UX elements you need, this also helps you to visualise the data your server will need to respond with.
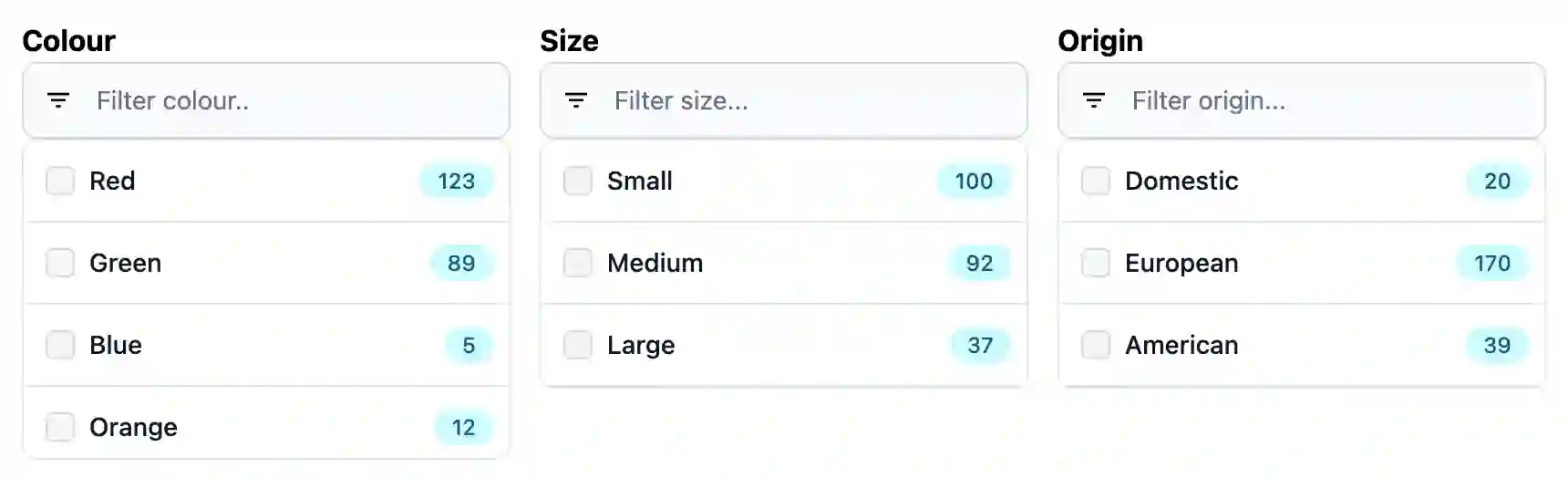
As you can hopefully see from the image above, the user can filter the fruit by colour, size and origin. When a user selects a colour, the other categories update to show the number of fruits that match the criteria they have selected, the numbers in the category to which the filter has been applied do not change, this shows the user how many additional results will be added if they select one of these. It's obvious that your customers will celebrate that they no longer have to scroll through pages of fruit to find the perfect apple.
The rules of the facets
- Each facet can have multiple values, e.g. the colour facet could have values of red, green, yellow, etc.
- A filter applied to a facet should only affect the counts of the other facets and not the facet to which the filter pertains. E.g. if a user selects red, the counts of the other colours should not change.
- In a system with pagination, the counts should be calculated for the entire dataset, not just the current page. This means any global filters/search should be applied to the counts.
Faceting in Postgres
Let's have a look at a mechanism for implementing faceting in Postgres.
It's important to note here that this is intended to be implemented with the aid of a high level language such as Java, TypeScript, etc. and not just in SQL. This is because the query will need to be dynamic based on the user's selections.
Let's look at a sample of our dataset, we have a table called fruit:
| Name | Colour | Size | Origin |
|---|---|---|---|
| Apple | red | medium | domestic |
| Banana | yellow | large | american |
| Blueberry | blue | small | domestic |
| Cherry | red | small | european |
| Durian | green | medium | american |
It has columns for the name, colour, size and origin of the fruit. From this list of columns, we wish to facet on the latter three.
The first step for creating the facets is simply counting each of the values for each of the columns. We can do this with a query like the following:
SELECT facet_name, jsonb_object_agg(COALESCE(facet_value, 'null'), count) AS facet_values
FROM (
SELECT facet_name, facet_value, COUNT(*) AS count
FROM "fruit",
LATERAL (VALUES ('colour', "colour"), ('size', "size"), ('origin', "origin")) facets(facet_name, facet_value)
GROUP BY facet_name, facet_value
) facets
GROUP BY facet_name;This yields an output of:
| facet_name | facet_values |
|---|---|
| colour | { "red": 2, "yellow": 1, "green": 1, "blue": 1 } |
| size | { "medium": 2, "large": 1, "small": 2 } |
| origin | { "domestic": 2, "american": 2, "european": 1 } |
What we have above is great, it provides the counts for each of the facetable columns. However, we need to be able to filter these counts based on the user's selections. Let's change the query as if a user has selected colour: red and size: medium:
SELECT facet_name, jsonb_object_agg(COALESCE(facet_value, 'null'), count) AS facet_values
FROM (
SELECT facet_name, facet_value, COUNT(*) AS count
FROM "fruit",
LATERAL (VALUES ('colour', "colour"), ('size', "size"), ('origin', "origin")) facets(facet_name, facet_value)
WHERE "colour" = "red" AND "size" = "medium"
GROUP BY facet_name, facet_value
UNION ALL
SELECT 'colour' AS facet_name, "colour" AS facet_value, COUNT(*) AS count
FROM "fruit"
WHERE "size" = "medium"
GROUP BY facet_name, facet_value
UNION ALL
SELECT 'size' AS facet_name, "size" AS facet_value, COUNT(*) AS count
FROM "fruit"
WHERE "colour" = "red"
GROUP BY facet_name, facet_value
) facets
GROUP BY facet_name;This yields an output of:
| facet_name | facet_values |
|---|---|
| colour | { "red": 1, "green": 1 } |
| size | { "medium": 1, "small": 1 } |
| origin | { "domestic": 1 } |
Notice that we can still see colours and sizes that were not selected, but that have matching fruit from other applied filters. I.e. even though red was selected, there is still another green fruit that is also medium in size.
The query needs to be dynamically created based on the user's selections with various pieces of it being added and altered such as the where clauses. This is fairly trivial to do in a high level language but remember to ensure that user input is sanitised to prevent SQL injection attacks.
Conclusion
In this post, we explored the concept of faceting and how it can be implemented in Postgres. We also looked at how to filter the facets based on user selections. This is a great way to provide a flexible and powerful search mechanism to your users.
Further reading:
- A useful Cybertec post on faceting by Ants Aasma. This also explores a more optimal way to implement faceting in Postgres.
- Information on the
LATERALkeyword in Postgres can be found on the official documentation
Please feel free to share your thoughts and questions about this post!